
This blog is part of the VTPP (VNET Threat Perception Platform) project, a three-year programme co-funded by the European Commission under the DIGITAL-ECCC-2022-CYBER-03 call. The project covers DDoS mitigation with FastNetMon, vulnerability scanning with OpenVAS, custom AI/ML detection plugins for Zeek, HSM-backed key management, RPKI validation and a Krill CA, and a full-scale deployment of Security Onion as the IDS/SIEM/NSM backbone.
Until recently, VNET’s network security visibility resembled a typical NetFlow-based setup: edge routers exported flow records to Vflow, which fed a single-server Elastic/Logstash/Kibana stack. The setup could catch volumetric DDoS and traffic-spike history, but with the flow metadata stopping at the packet header, anything requiring payload or protocol context was out of reach. That is the baseline the VTPP project – VNET Threat Perception Platform – was built to replace.
This post is about that last piece, and specifically about a decision to run the Security Onion sensor nodes as virtual machines on our existing OpenStack fabric, not on dedicated bare-metal appliances. First we will talk about why we chose this route, then we will cover the technical „how“.
Security Onion in one paragraph
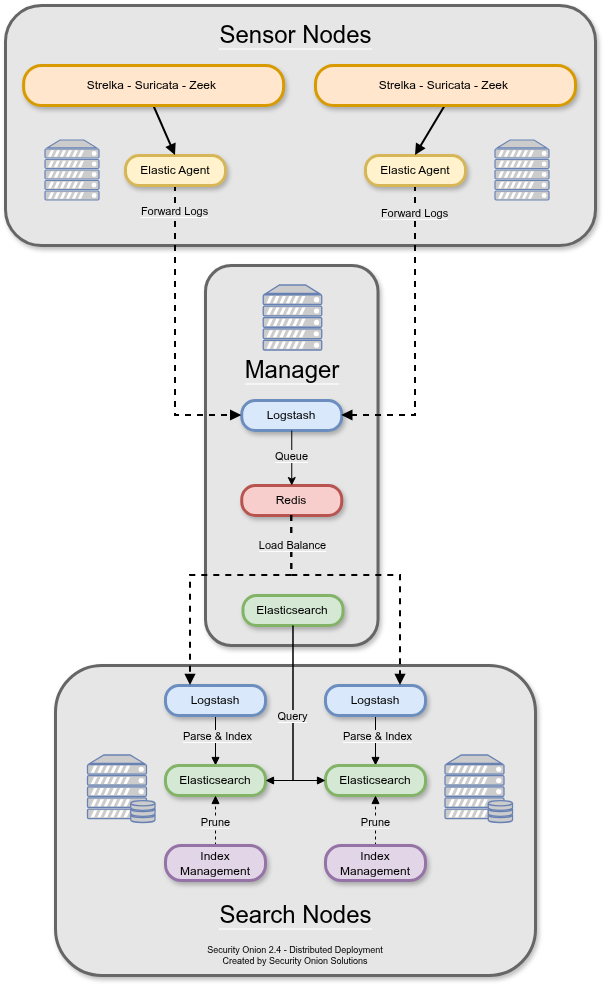
Security Onion 2.4 is an open-source network security monitoring distribution that bundles Suricata (signature-based IDS/IPS), Zeek (protocol-aware traffic analysis), Stenographer (full-packet capture), Strelka (file analysis), the Elastic stack (Elasticsearch, Logstash, Kibana), and a custom web UI (SOC). In a distributed deployment the roles split three ways. A manager node runs SOC, Logstash, Redis, Kibana, ElastAlert. Search nodes pull events from Redis and own their own Elasticsearch shards. Sensor nodes (also called „forward nodes“) sit on the capture links, run Suricata and Zeek against live traffic, and ship their alerts and logs over Elastic Agent to the manager. That last role is the interesting one. Everything upstream can be scaled in the usual way. The sensor is where packet rate meets reality.
The scale we operate at
Some numbers from the current production grid, taken from our August 2025 performance report:
- Four sensor instances, one at each of our four points of presence: the SIX peering exchange, the Sitel peering exchange, the SHC3 datacenter, and the DC Digitalis datacenter
- Aggregate mirrored traffic: 65 to 70 Gbit/s in prime-time hours
- Packet rate: more than 9 million packets per second across the grid
- Flow rate: roughly 110,000 flows per second
- Security Onion grid event rate: 21,000+ EPS into Logstash
- Storage: 54 TB of usable capacity on HPE Alletra Storage MP, up from 3 TB on the legacy setup
- Retention: Zeek logs and Suricata alerts persisted end-to-end, full PCAP on a short rolling tier
Per-sensor, the mirror ingress varies by PoP (Point of Presence). The DC Digitalis sensor is the busiest – 18 Gbit/s average, peaking around 27 Gbit/s – while the SIX sensor averages around 12 Gbit/s and peaks near 21 Gbit/s. A single sensor still processes hundreds of terabytes a week: Sensor 1 saw 883 TB of mirrored traffic over the six-day window in the graph below.
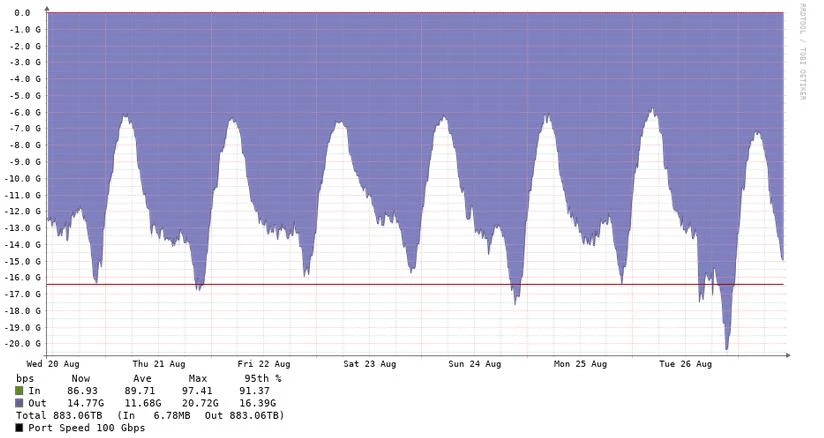
Mirrored traffic on Sensor 1 (SIX PoP), 20–26 August 2025 — avg ~12 Gbit/s, peak ~21 Gbit/s, 883 TB cumulative
The non-obvious decision: virtual, not physical
Here’s where the project deviates from the documented path. The Security Onion hardware guide is unambiguous about sensors: „We recommend dedicated physical hardware (especially if you’re monitoring lots of traffic) to avoid competing for resources.“
But for us, even with the 70 Gbit/s deployment, OpenStack was still the preferred way.
The capture-capable compute hosts are Dell PowerEdge 2U servers. Each is dual-socket AMD EPYC (3.25 GHz base, 128 threads per host), 768 GB DDR5, a dual-port Broadcom 100 GbE QSFP NIC dedicated to packet capture and a Broadcom dual-port 25 GbE card for the OpenStack management and backend networks. Storage is 32 Gbit Fibre Channel over redundant fabrics into an HPE Alletra Storage pair with synchronous replication between the two datacentres. These compute hosts also run the Security Onion manager and both search nodes, all on Oracle Linux 9 with the UEK kernel, and share hardware with the other VTPP platforms – OpenVAS, FastNetMon, RPKI validators, Krill CA – and with unrelated tenant workloads.
The project proposal’s original shape was a fleet of dedicated physical boxes – four sensor servers, two search, one manager, plus more for OpenVAS and RPKI. What we actually deployed is virtual machines on three capture-capable compute hosts in an already existing OpenStack region, because virtualisation lets us pack those workloads onto shared hardware without a capture-rate penalty.
Why virtualise a sensor
The usual virtualisation pitch – „save hardware, save money“ – isn’t really the fuel behind this decision. Each sensor still consumes one dedicated 100 Gbit NIC and its own pool of CPU cores, whether it runs on bare metal or inside a VM. PCI passthrough is one-to-one, so virtualisation doesn’t let you squeeze two sensors‘ worth of mirror traffic through one NIC. And the VM route adds its own costs: some hypervisor overhead, plus the one-time effort of getting passthrough configured and tuned. The real case for running sensors as VMs is operational, not hardware savings. Four operational benefits mattered enough for us to override the Security Onion guidance:
1. Infrastructure reuse, the actual kind We already operate OpenStack. We already have the monitoring agents, the Zabbix templates for NVMe wear, the SAN backup cadence, the IPAM, the patch pipeline, the alerting rules, and the runbooks that the rest of our fleet uses. Standing up a parallel bare-metal fleet of Security Onion servers is not „free“ – it is a second class of machines with its own BMC tooling, its own imaging pipeline, its own drift-detection problem. Putting sensors on OpenStack meant we inherited all of that. A new sensor gets the same Zabbix template as any other VM. The SAN snapshots its root disk on the same schedule as everything else. The oncall runbook is one runbook.
2. Backups and disaster recovery that are minutes, not hours A Security Onion sensor is not a trivial rebuild. so-setup is interactive, the node has to be reintroduced into the grid, Suricata rule tuning and BPF filters need to be replayed, the firewall host-group memberships have to be re-applied in SOC. On bare metal, drive failure or a corrupted root filesystem could lead to a multi-hour recovery timeline even with config management. On OpenStack, the sensor’s root volume is snapshot-backed on the Alletra Storage and a full rebuild is „boot from snapshot“ plus a so-restart to bring the grid-facing services back up. The capture NIC binding comes back automatically.
3. Compute consolidation for the non-capture nodes A Security Onion manager and its two search nodes do not individually need 100 Gbit, 64 cores, or 768 GB of RAM. On bare metal, they would still get allocated rack units, power, network cables, and switch ports. On our OpenStack fabric, all three are plain 8 vCPU / 32 GB RAM VMs on the same public flavor we use for ordinary customer workloads, sharing compute hosts with the sensor VMs and with unrelated tenants. The manager’s 1 TB /nsm volume is an FC-backed Cinder volume on the Alletra Storage. The alternative is three more physical servers sitting idle at 5 % CPU most of the day, which was not our preferred way.
4. Horizontal scale that is an API call Adding a sensor costs one 100 Gbit port on the right NCS-5500, one monitor-session stanza, and one openstack server create against the existing capture flavor. No procurement, no rack-and-stack, no BMC bring-up. The same applies to rolling a sensor to a new compute host: cold-migrate the VM. If the project decides tomorrow to add a sensor mirroring a new peering session, we can have it in the grid before lunch.
There is an honest flip side. Virtualisation is a poor fit when you don’t already operate a mature hypervisor platform – you’re trading one ops problem for another. It’s also a poor fit when a single sensor’s throughput demand genuinely exceeds what one host NIC can provide. If you need 400 Gbit on one capture instance, bare metal with a specialised capture card is the better path. And it adds failure modes – a hypervisor crash could take both sensors on a shared host down together, where two bare-metal appliances would fail independently. Our answer to this is horizontal redundancy (four sensors in four PoPs) and a conservative patch cadence on the compute hosts that run sensors.
SR-IOV vs full PCI passthrough
None of the four operational benefits above matter if the VM can’t actually sniff at line rate. Virtio networking tops out around 10–15 Gbit/s with average packets, and even lower with small ones. We’ve seen a few million packets per second per sensor, well above what a single vhost-net thread can push. The fix is to take the hypervisor out of the packet path entirely and hand the physical 100 Gbit port to the guest as a passthrough PCIe device.
OpenStack gives us two realistic ways to hand a VM direct hardware access. SR-IOV splits the physical function (PF) into virtual functions (VFs), each looking like an independent NIC to a VM – the usual choice when many VMs need to share NICs with near-native performance. Full PF passthrough gives one VM the whole physical function, and the VM’s driver talks to the hardware exactly as a bare-metal host would.
For a Security Onion sensor there’s no reason to share – the only consumer is the sensor’s capture stack. With full PF passthrough, the guest sees a Broadcom BCM57508 through plain bnxt_en, exactly as it would on a dedicated server, with the same queue count and filter capabilities the hardware exposes.
The OpenStack configuration – minimal, on purpose
The Nova PCI configuration on the capture-capable compute hosts is three lines:
# /etc/nova/nova.conf on the compute node:
[pci]
passthrough_whitelist = [{"vendor_id": "14e4", "product_id": "1750"}]
alias = {"vendor_id": "14e4", "product_id": "1750", "device_type": "type-PCI", "name": "100g-nic"}14e4:1750 is the Broadcom BCM57508 NetXtreme-E, the match is by vendor/product, not by PCI address, so Nova will hand out any available BCM57508 PF when a VM is scheduled onto the host. The compute host’s kernel cmdline is likewise unspectacular – amd_iommu=on and nothing else specific to capture. No static vfio-pci ids=… entry in /etc/modprobe.d/. No reserved 1 GiB hugepages on the boot line. No isolcpus. The host is a general-purpose OpenStack compute node that happens to have a 100 Gbit NIC earmarked for passthrough.
The sensor flavor is equally brief:
$ openstack flavor show vtpp-16vcpu-32GRAM-100gnic -f yaml
name: vtpp-16vcpu-32GRAM-100gnic
vcpus: 16
ram: 32768
disk: 0
properties:
pci_passthrough:alias: 100g-nic:1One property. That’s all it requires.
This runs against the standard advice for high-PPS virtualisation, and it’s worth being precise about why it works for us:
- Transparent hugepages are close enough. The host has transparent_hugepage=always. At any moment around 450 GiB of the 768 GiB host memory shows up as AnonHugePages in /proc/meminfo. Guest RAM is anonymous from the host’s point of view, so khugepaged coalesces most of it into 2 MiB pages without anyone asking explicitly. Reserved 1 GiB hugepages would give slightly lower TLB miss rates at our packet sizes – probably single-digit percent – but also sequester memory permanently from the rest of the cloud. We didn’t see a capture-rate problem that would justify it.
- NUMA affinity happens by geography. Both 100 Gbit PFs on each compute host are physically on NUMA node 0 (/sys/bus/pci/devices/0000:64:00.0/numa_node reads 0). Linux’s first-touch allocator tends to place guest RAM on whichever node the vCPUs run on, and Nova’s scheduler picks the less-loaded node. Remote-NUMA memory traffic isn’t our bottleneck. If it becomes one, hw:numa_nodes=1 is a one-line flavor edit away.
- CPU pinning matters when the host is oversubscribed. Ours aren’t. 128 logical CPUs on dual-socket EPYC 9354 gives the CFS scheduler enough slack that two 16-vCPU sensors plus tenant VMs don’t meaningfully contend for cores. With per-sensor averages of 10–20 Gbit/s and peaks around 26 Gbit/s on the busiest link, the scheduler handles it. If the ratio got tighter, hw:cpu_policy=dedicated is the next step.
The one knob we do care about is the PCI passthrough itself, and libvirt does most of the work. With the hostdev entry in the domain XML set to managed=’yes‘, libvirt unbinds the device from bnxt_en and rebinds it to vfio-pci at VM start, then reverses it at shutdown. We can confirm the binding on the host while the VM is running – lspci -nnk shows Kernel driver in use: vfio-pci on the BCM57508 PFs for as long as the guest owns them.
Inside the guest – Oracle Linux 9.7 with UEK 5.15 – the NIC appears as a native PCIe device at 0000:00:06.0, 14e4:1750, driver bnxt_en, firmware 229.2.54.0 / pkg 22.92.06.10. ethtool -i output is identical to what a bare-metal host would show. We then do three things in the guest:
- Disable every coalescing offload so Suricata and Zeek see original on-wire frames rather than GRO/LRO-reassembled ones. After ethtool -K ens6np0 gro off lro off tso off gso off sg off, ethtool -k confirms generic-receive-offload, large-receive-offload, tcp-segmentation-offload, generic-segmentation-offload and scatter-gather all read off.
- Raise MTU to 9000. Our core network carries jumbo frames, so the capture interface is set to 9000 bytes (guest NIC, bond, Suricata reader) to avoid truncating any frame that crosses the mirror.
- Bond the capture interface. Rather than hand the raw ens6np0 to Suricata, we place it as the sole slave of a Linux bond (bond0, round-robin mode). Suricata reads from bond0. The cost is effectively zero (one bond driver pass per packet) and the benefit is that adding a second 100G passthrough later (for a second mirror feed or multi-link scale-out) is a bond enslavement, not a Suricata reconfiguration. Security Onion itself ships a helper (/usr/sbin/so-combine-bond) for the bonded-capture case, so this isn’t an out-of-tree pattern.
Security Onion runs Suricata in a Docker container configured to read from bond0 via af-packet. The af-packet section in suricata.yaml uses flow-based clustering with 7 worker threads, tpacket-v3, a 5,000-frame ring, 69,632-byte blocks, mmap-enabled capture, and kernel-side checksum verification. Security Onion sets sensible defaults. This is the shape we converged on for our traffic profile, and it’s a useful starting point if you’re sniffing multi-gigabit streams in a guest.
The other end: Cisco NCS-5500 monitor-session
The 100G mirror traffic comes from a Cisco NCS-5500 running IOS-XR. The configuration is unremarkable – the point of including it is to show the full path end-to-end. A representative monitor-session, from one of our NCS routers to its local sensor compute host:
monitor-session ms1 ethernet
destination interface HundredGigE0/0/0/27
!
interface HundredGigE0/0/0/24
monitor-session ms1 ethernet direction rx-only port-level
!
interface HundredGigE0/0/0/26
monitor-session ms1 ethernet direction rx-only port-level
!HundredGigE0/0/0/27 is the destination port, patched into a compute host’s 100G capture NIC. From there, vfio-pci has claimed the PF, Nova has mapped it into the sensor VM as ens6np0, the guest’s bnxt_en receives the mirrored frames into its RX rings, the bond driver hands them up unchanged, and Suricata’s af-packet worker threads pick them off the ring. There is no hypervisor data path on that port. The only difference from a bare-metal sensor is that the root filesystem lives on FC-attached Alletra Storage instead of a local RAID.
A couple of nuances worth knowing
Live migration is not an option. A VM with a passthrough PCIe device is tied to one compute host. Cold migration works – openstack server migrate shuts the VM down, Nova re-binds the passthrough device on the target host (which must have the same vendor/product alias available), and the VM boots. But live migration assumes the device can be hot-unplugged from the running guest, and that’s not how vfio-pci passthrough works. For sensors this is fine. Our redundancy model is „have another sensor in another PoP,“ not „migrate this one in-flight.“
PCI-address pinning vs. vendor-ID matching. Early passthrough_whitelist entries elsewhere in our cloud used an explicit PCI address. Moving the card to a different slot or adding a second capture NIC then required a Nova config change and a nova-compute restart before the scheduler saw the new device. The vendor/product match – {„vendor_id“: „14e4“, „product_id“: „1750“} – lets Nova hand out any available BCM57508 PF, and adding a capture NIC becomes a hardware task rather than an OpenStack one. The whitelist also stops going stale when PCI enumeration shifts after a board replacement.
Two sensors on one compute host
One last note on scheduling. Both sosensor1 and sosensor2 currently live on the same compute host with one BCM57508 PF passed through to each, and the third SHC3 sensor on the neighbouring compute node. The co-location wasn’t forced by an affinity rule. The Nova scheduler landed them there because the host had two available 100g-nic aliases and capacity for two 16-vCPU / 32 GB VMs. That’s the consolidation win in practice: two independent 100 Gbit captures running on one chassis, each with its own passthrough port and its own set of vCPUs out of the host’s 128 logical cores, alongside several unrelated tenant VMs.
On bare metal, the same coverage would be two physical servers. On OpenStack with PCI passthrough it’s one chassis, one hypervisor, two flavor bookings. A third sensor on the same host would require fitting a second BCM57508 card, as the existing one is dual-port and both ports are taken, but the OpenStack side is still a simple VM create call. The consolidation, not the theoretical per-VM performance, is the single biggest reason we took this path.
Closing
After running this setup in production for close to a year now, it’s interesting to see how little configuration it took. The Nova and flavor config that makes the whole thing possible is a handful of lines, not the dense table of NFV-style tuning knobs we expected going in. Transparent hugepages, libvirt’s managed=’yes‘ passthrough, Linux’s default NUMA allocator and a compute host with enough slack: together they do most of the job, and the tuning we actually did is inside the guest – disabling offloads, raising MTU, wiring Suricata’s af-packet correctly. The knobs that OpenStack-NFV guides front-load – CPU pinning, explicit NUMA topology, static 1 GiB pages – are available if we ever need them, but we haven’t, and the flavor is simpler for not pre-reserving them.
The sensors snapshot like any other VM, recover fast from failure, share hardware with the rest of VTPP’s platforms (OpenVAS, FastNetMon, the RPKI validators), and carry our most interesting traffic. The 21,000+ EPS arriving at the grid’s Logstash is the number that matters.
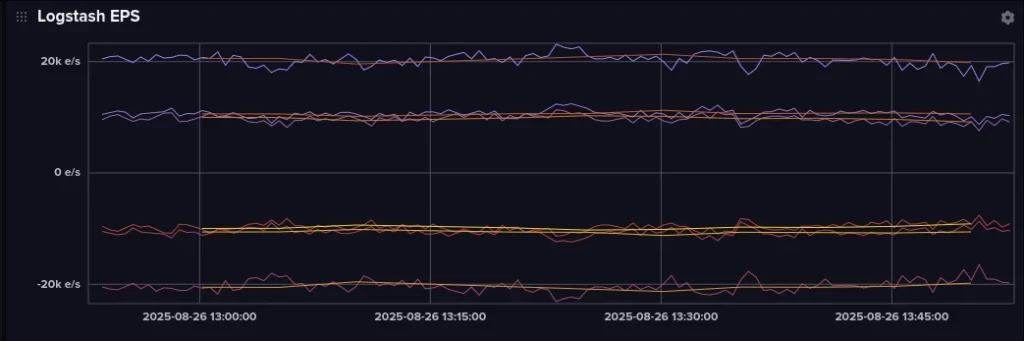
Logstash events-per-second across the grid. Source: VTPP performance report, August 2025
The caveat goes with it. This works for our traffic profile: four sensors sharing an aggregate 65–70 Gbit/s, with each VM averaging well below its 100 Gbit port. If you need a single sensor sustaining 100 Gbit/s with small packets, OpenStack-NFV tuning will be needed. The Security Onion docs‘ „prefer physical hardware“ advice is the right default – but for many ISP-scale IDS deployments a plain OpenStack flavor with one PCI-passthrough alias turns out to be enough.

Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Cybersecurity Competence Centre. Neither the European Union nor the granting authority can be held responsible for them.